
This week’s tech rout hit like a sledgehammer. The Nasdaq bled red, the VIX spiked, and US markets notched their worst day in weeks, and the ASX followed.
But overnight brought a tentative recovery. Traders bought the dip, and volatility retreated.
It’s hard to say if this was just a bout of profit-taking on the road higher for markets. No one knows how long this run can continue.
But it seems like the North Star of US tech, which has guided portfolios for years, is starting to flicker.
The Spending Machine Continues to Grow
Tech earnings are still rising. That’s the good news.
The bad news? Capex spending has reached monstrous proportions.
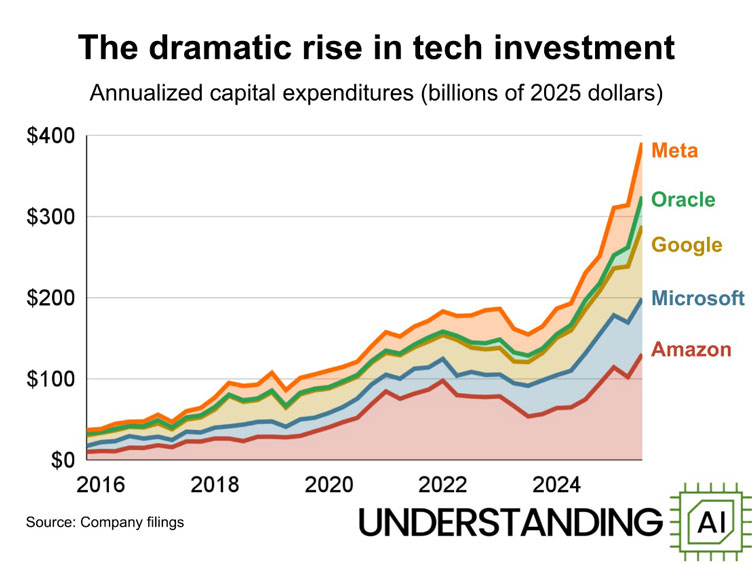
Source: Understanding AI
And it’s not like investors aren’t taking notice. Meta’s latest spending plans sent investors running for the exits.
Despite spending billions to poach top talent, they’ve yet to launch a single product.
AMD reported soaring sales, yet shares barely budged. The gap between expectations and reality has become a chasm.
Microsoft, Google, and Meta will spend a combined US$200 billion on AI infrastructure this year. Their actual AI revenue? Only a quarter of that.
We’re funding the most expensive science experiment in history — with shareholders’ money.
Investors are starting to get anxious that we haven’t heard a peep from the biggest tech names in some time.
While they have been looking North, I’ve been hunting elsewhere.
China’s Memory Breakthrough
Once again, small Chinese labs are bending the paradigm of AI.
While Silicon Valley burns cash on brute force computing, China just solved AI’s biggest bottleneck.
It’s called Kimi Linear, and it addresses what I’ve been calling the ‘goldfish memory’ problem.
Here’s the issue, simply put: Current AI is like a brilliant student who forgets everything after each exam. It can ace any test but can’t remember what it learned yesterday.
This is because it examines the relationship between every word, and every other word.
This is what makes AI (Large Language Models) so powerful. But also, so expensive.
If you double the text length, you quadruple the costs.
There have already been workarounds to this problem, but nothing robust.
This is why AI assistants need constant reminders. And why those billion-dollar models still can’t replace a competent employee at a complex job.
Kimi Linear has the potential to change that. The system processes information 6× faster (and cheaper) while handling over 1 million tokens of context.
1 million tokens are roughly 750,000 words. A bit over the entire length of War and Peace.
Current AI struggles with 100,000 tokens. Kimi handles ten times that — entire books, complete codebases, years of emails — all held in memory simultaneously.
Below you can see Kimi Linear compared to our previous best efforts (also from China, labelled MLA) when working with 128,000 to 1 million tokens.
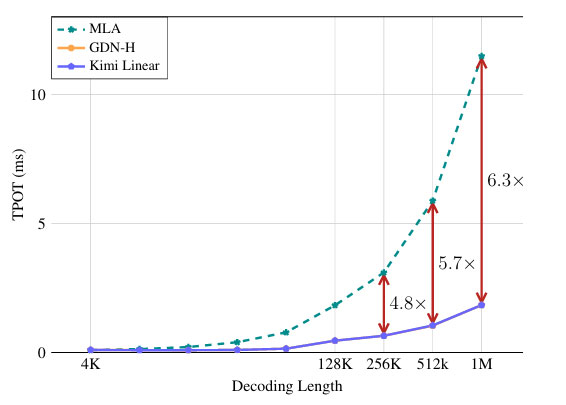
Source: Kimi Linear
The breakthrough uses a novel approach that, in simple terms, you can think of as ‘learning to forget’.
Essentially, teaching AI to compress memories like our brains do. Keeping the vital stuff while forgetting the trivial.
Why does this matter for your portfolio?
Without memory, AI can’t truly replace workers. Can’t justify the spending. Can’t deliver the productivity revolution everyone’s betting on.
The uncomfortable truth is that yet again, a breakthrough didn’t come from Silicon Valley or London. It came from a Chinese AI lab.
China isn’t just manufacturing our phones anymore. They’re innovating the core infrastructure of tomorrow’s economy.
Yes, Kimi Linear is still a band-aid on a bigger wound. But it’s a band-aid that’ll keep the AI scaling story alive.
And potentially shifts the innovation narrative eastward.
Edison Rises Again
Before you pivot your portfolio to Shanghai, some hope is emerging from the West.
Edison AI just released Kosmos, an AI scientist with incredible potential.
Kosmos can do six months of scientific work in a single day. It can read 1,500 research papers, write 42,000 lines of code, and produce findings that are 79% reproducible.
Kosmos has already made seven validated discoveries across neuroscience, materials science, and clinical genetics. Three reproduced unpublished findings. Four are entirely new contributions to science.
As Edison’s founders put it: ‘AI-accelerated science is here.’ Not coming. Here.
The North Star isn’t dead; it’s becoming a wider constellation.
I’ve argued in the past that China continues to push towards making AI a commodity.
If this occurs, then the monolithic US tech narrative could fragment into smaller opportunities for investors.
Edison proves you don’t need to boil the ocean to create value.
Your portfolio may need to reflect this new reality soon.
The North Star got us here. But it won’t get us where we’re going.
Regards,
Charlie Ormond,
ATLAS and Altucher’s Investment Network Australia

Comments